


Kite Release Notes – August 2019
We’re thrilled to share the improvements that we shipped this summer for Kite. Read on to learn about the enhanced completions intelligence, proxy support, and performance optimizations we shipped in August.
- Performance improvements (memory and CPU)
- Improved type inference for better completions
- Proxy support
- More to come
Performance improvements (memory and CPU)
Memory optimizations
We know how critical memory is for development, so we’ve put a lot of engineering effort into minimizing Kite’s memory impact. We’ve seen the biggest savings on three fronts:
- We optimized the encoding of various datasets that Kite uses, like Kite’s Python docs and global type information. As a result, less memory is wasted by the decoder, which also results in less work for the garbage collector.
- Our ML team downsized the size of Kite’s ML models without compromising performance using embedding compression techniques.
- Finally, we’ve made several changes enabling us to free more memory (local code indexes, in-memory datasets, and ML models) when Kite goes idle. Kite now has a much smaller footprint for users who leave it running in the background.
CPU optimizations
In many cases, our memory optimizations also helped CPU utilization, but we went a step further when it came to garbage collection.
Kite allocates many short-lived objects in memory when performing code analysis and inference as you’re typing. Consequently, garbage collection is one of the biggest consumers of CPU when you use Kite.
To alleviate this, we implemented memory pooling to reuse memory amongst these short-lived objects, thereby drastically reducing the amount of garbage collection that needed to be done. As a result, we saw substantial improvements in CPU utilization for users.
Note: These efforts are ongoing, and we still have further optimizations underway. If you’re experiencing memory or CPU issues while using Kite, please contact us at support@kite.com and include logs that you can find here that will help us debug your specific issue.
Improved type inference for better completions
Type inference refers to the problem of being able to determine the type of a symbol in a codebase. In the context of completions, type inference is a foundational problem because in order to know what attributes are available on an object to show completions for, the object’s type must be known first.
Why type inference is key for great completions
The type inference upgrades we released enable Kite to know the type of the symbol underneath your cursor more often, and therefore, show you completions more often. More subtly, better type inference results in better data to use to train our machine learning models, resulting in more accurate completions to help you code faster.
Most modern Python completions engines use static analysis to perform type inference, and Kite is no exception. However, Kite also uses several other techniques to enhance its type inference. The difference in completions quality between Kite and the typical completions engine can be seen in the function call below:
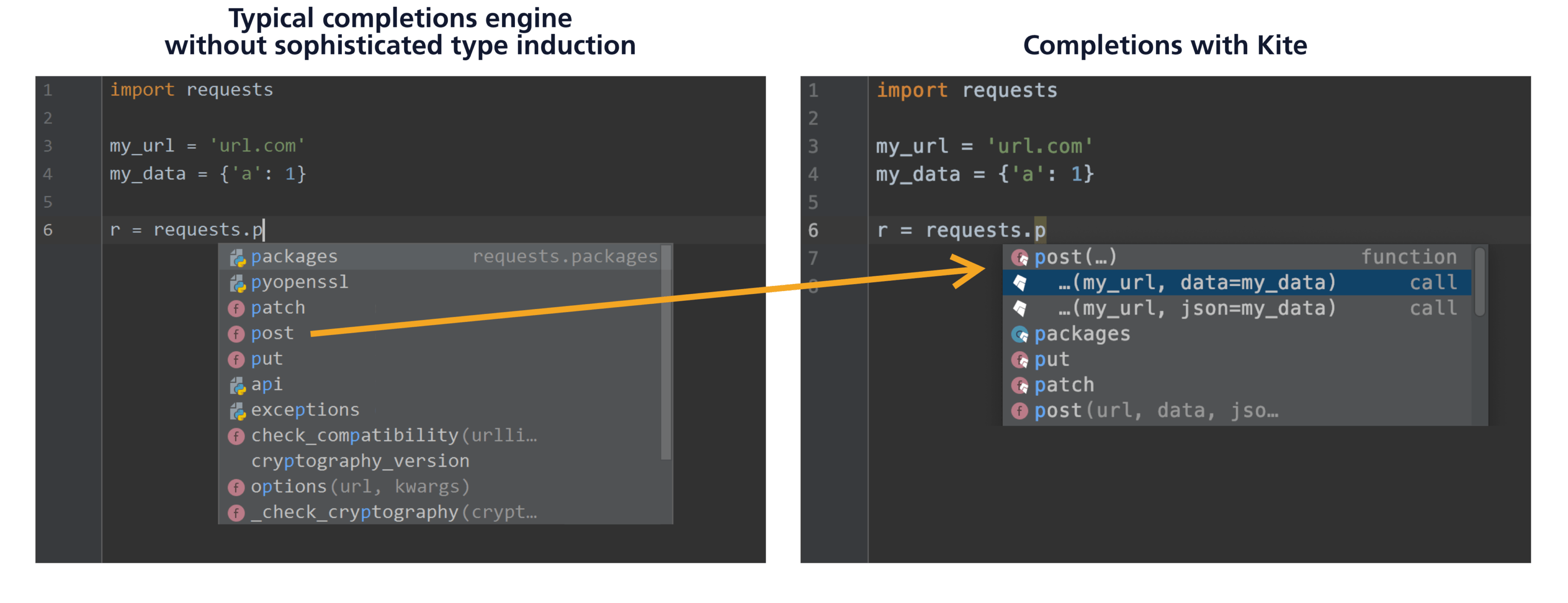
We recently improved upon four of Kite’s type inference techniques.
1. Type induction
First, we added type induction to Kite’s engine to help determine types. We’ve built probabilistic models to infer the type of an object based on the names of the attributes accessed on that object. By doing so, Kite learned the return types of 100,000 additional functions from the most popular Python packages – a massive improvement over any existing completions engine.
2. More static analysis
Second, we expanded our static analysis of a greater amount of third-party Python libraries. This work added the return types of 32,000 additional functions, giving Kite the widest completions breadth of any tool.
3. Parsing docstrings
Third, Kite now parses docstrings to determine the returns types of functions. Open source packages are usually documented with useful docstrings that contain this information. By parsing their docstrings, Kite learned the return types of 6,500 additional functions from the most popular Python packages.
4. Dynamic analysis
Finally, we used dynamic analysis to generate new datasets for use in our code analysis pipeline. Unlike static analysis, dynamic analysis determines types in an actual runtime environment and can therefore determine types with 100% certainty. Using dynamic analysis has allowed us to learn the return types of 800 additional functions from the most popular Python packages.
Proxy support
Adding proxy support used to be the number one feature request we received from our users. Now proxy support is available so that you can use Kite behind your company’s proxy if it has one.
Kite will try to detect your proxy configuration from your system automatically so that you don’t need to do anything. However, you can also configure it manually by opening the Copilot, clicking on the settings icon in the lower right corner, and then by clicking on “Custom” for the proxy.
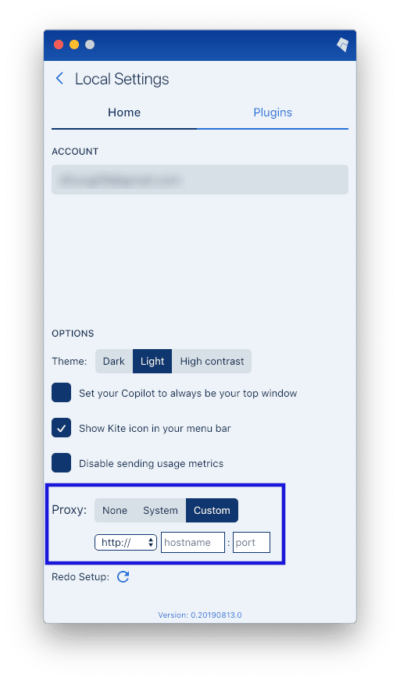
Please note that the http:// option will work for both HTTP and HTTPS proxies.
Since we first launched Kite, we’ve been changing the product to make it more accessible in a workplace setting. Making Kite work completely on your local machine was the first (and big!) step and adding proxy support represents yet another step towards making Kite the perfect tool to use at work.
More to come!
We have more news coming your way about new autocomplete features and editor integrations – stay tuned! Make sure to follow @kitehq on Twitter, and share Kite with your friends.
In the meantime, if you have feedback about Kite, we’d love to hear it at feedback@kite.com.
Resources
 in San Francisco
in San Francisco