


Web Scraping with Python: A Tutorial on the BeautifulSoup HTML Parser
Introduction
Web scraping is a technique employed to extract a large amount of data from websites and format it for use in a variety of applications. Web scraping allows us to automatically extract data and present it in a usable configuration, or process and store the data elsewhere. The data collected can also be part of a pipeline where it is treated as an input for other programs.
In the past, extracting information from a website meant copying the text available on a web page manually. This method is highly inefficient and not scalable. These days, there are some nifty packages in Python that will help us automate the process! In this post, I’ll walk through some use cases for web scraping, highlight the most popular open source packages, and walk through an example project to scrape publicly available data on Github.
Web Scraping Use Cases
Web scraping is a powerful data collection tool when used efficiently. Some examples of areas where web scraping is employed are:
- Search: Search engines use web scraping to index websites for them to appear in search results. The better the scraping techniques, the more accurate the results.
- Trends: In communication and media, web scraping can be used to track the latest trends and stories since there is not enough manpower to cover every new story or trend. With web scraping, you can achieve more in this field.
- Branding: Web scraping also allows communications and marketing teams scrape information about their brand’s online presence. By scraping for reviews about your brand, you can be aware of what people think or feel about your company and tailor outreach and engagement strategies around that information.
- Machine Learning: Web scraping is extremely useful in mining data for building and training machine learning models.
- Finance: It can be useful to scrape data that might affect movements in the stock market. While some online aggregators exist, building your own collection pool allows you to manage latency and ensure data is being correctly categorized or prioritized.
Tools & Libraries
There are several popular online libraries that provide programmers with the tools to quickly ramp up their own scraper. Some of my favorites include:
Requests– a library to send HTTP requests, which is very popular and easier to use compared to the standard library’surllib.BeautifulSoup– a parsing library that uses different parsers to extract data from HTML and XML documents. It has the ability to navigate a parsed document and extract what is required.Scrapy– a Python framework that was originally designed for web scraping but is increasingly employed to extract data using APIs or as a general purpose web crawler. It can also be used to handle output pipelines. Withscrapy, you can create a project with multiple scrapers. It also has a shell mode where you can experiment on its capabilities.lxml– provides python bindings to a fast html and xml processing library calledlibxml. Can be used discretely to parse sites but requires more code to work correctly compared toBeautifulSoup. Used internally by theBeautifulSoupparser.Selenium– a browser automation framework. Useful when parsing data from dynamically changing web pages when the browser needs to be imitated.
| Library | Learning curve | Can fetch | Can process | Can run JS | Performance |
requests |
easy | yes | no | no | fast |
BeautifulSoup4 |
easy | no | yes | no | normal |
lxml |
medium | no | yes | no | fast |
Selenium |
medium | yes | yes | yes | slow |
Scrapy |
hard | yes | yes | no | normal |
Using the Beautifulsoup HTML Parser on Github
We’re going to use the BeautifulSoup library to build a simple web scraper for Github. I chose BeautifulSoup because it is a simple library for extracting data from HTML and XML files with a gentle learning curve and relatively little effort required. It provides handy functionality to traverse the DOM tree in an HTML file with helper functions.
Requirements
In this guide, I will expect that you have a Unix or Windows-based machine. You might want to install Kite for smart autocompletions and in-editor documentation while you code. You are also going to need to have the following installed on your machine:
- Python 3
BeautifulSoup4Library
Profiling the Webpage
We first need to decide what information we want to gather. In this case, I’m hoping to fetch a list of a user’s repositories along with their titles, descriptions, and primary programming language. To do this, we will scrape Github to get the details of a user’s repositories. While this information is available through Github’s API, scraping the data ourselves will give us more control over the format and thoroughness of the end data.
Once that’s done, we’ll profile the website to see where our target information is located and create a plan to retrieve it.
To profile the website, visit the webpage and inspect it to get the layout of the elements.
Let’s visit Guido van Rossum’s Github profile as an example and view his repositories:
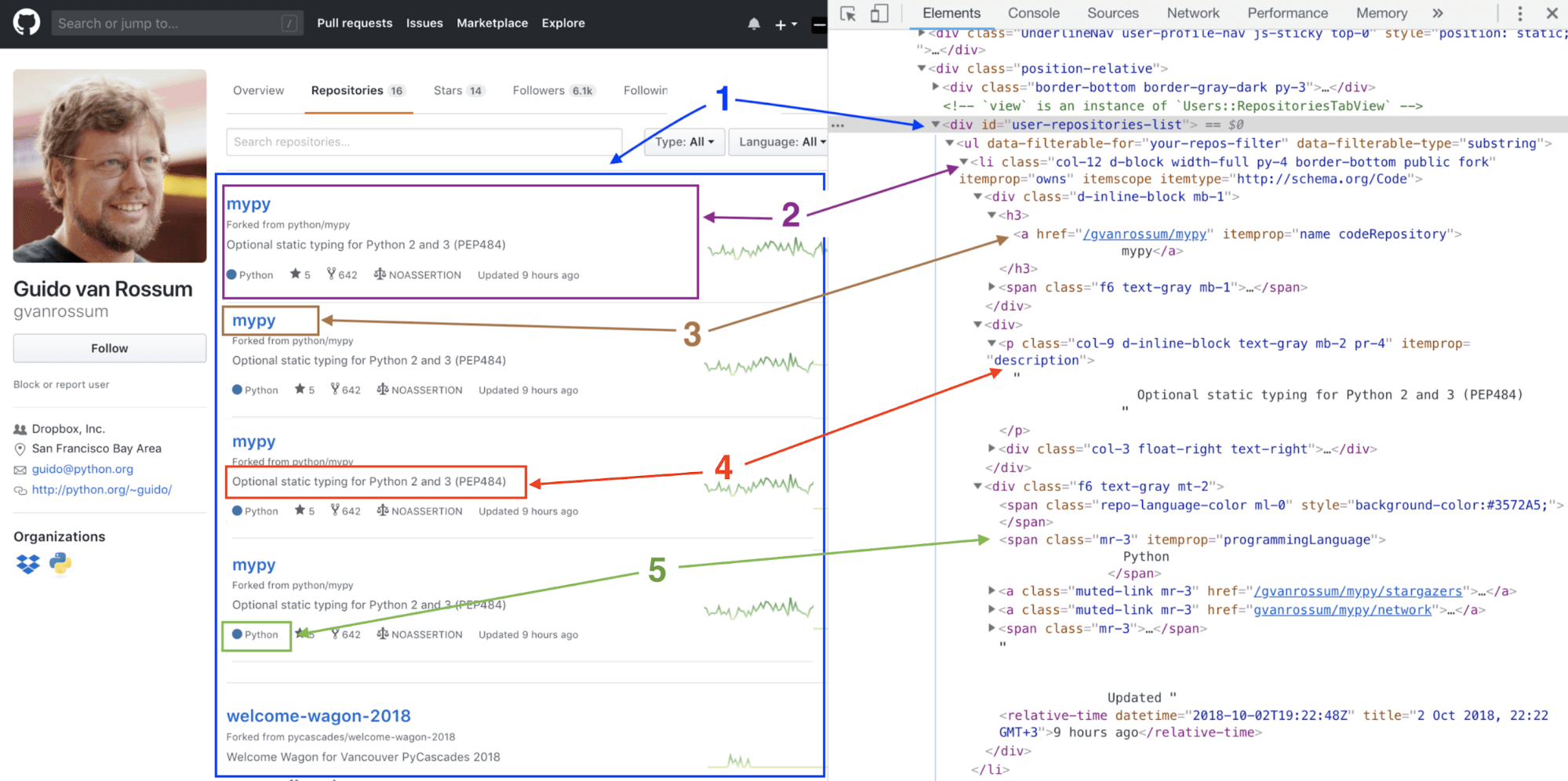
- The
divcontaining the list of repos From the screenshot above, we can tell that a user’s list of repositories is located in adivcalleduser-repositories-list, so this will be the focus of our scraping. This div contains list items that are the list of repositories. - List item that contains a single repo’s info / relevant info on DOM tree The next part shows us the location of a single list item that contains a single repository’s information. We can also see this section as it appears on the DOM tree.
- Location of the repository’s name and link Inside a single list item, there is a
hreflink that contains a repository’s name and link. - Location of repository’s description
- Location of repository’s language
For our simple scraper, we will extract the repo name, description, link, and the programming language.
Scraper Setup
We’ll first set up our virtual environment to isolate our work from the rest of the system, then activate the environment. Type the following commands in your shell or command prompt:
mkdir scraping-example
cd scraping-example
If you’re using a Mac, you can use this command to active the virtual environment:
python -m venv venv-scraping
On Windows the virtual environment is activated by the following command:
venv-scraping\Scripts\activate.bat
Finally, install the required packages:
pip install bs4 requests
The first package, requests, will allow us to query websites and receive the websites HTML content as rendered on the browser. It is this HTML content that our scraper will go through and find the information we require.
The second package, BeautifulSoup4, will allow us to go through the HTML content, then locate and extract the information we require. It allows us to search for content by HTML tags, elements, and class names using Python’s inbuilt parser module.
The Simple Scraper Function
Our function will query the website using requests and return its HTML content.
The next step is to use BeautifulSoup library to go through the HTML and extract the div that we identified contains the list items within a user’s repositories. We will then loop through the list items and extract as much information from them as possible for our use.
# The function to scrape a website
def scrape_website(url):
# query the web page
response = requests.get(url)
# parse the fetched HTML content using a HTML parser
# since our page content is going to be in HTML format
soup = BeautifulSoup(response.content, 'HTML.parser')
# find the repositories container div
main_content = soup.find('div', {'id': 'user-repositories-list'})
# Extract the list of repositories
list_or_repos = main_content.findAll('li')
# create a new list to put our extracted data
results = []
# Function to extract the details for each repo
for repo in list_of_repos:
# create a new repo's details dictionary
repository = {}
# add the repository name, note that we strip a leading newline and
# leading and trailing whitespaces
repository['name'] = repo.a.string.strip()
# Extract the base url for the url passed into the function
base_url = '{uri.scheme}://{uri.netloc}'.format(uri=urlparse(url))
# generate the repository link
repository['link'] = '{0}{1}'.format(base_url, repo.a.get('href'))
# Check if there is a repo description and add it to our dictionary
if repo.p and repo.p.string:
repository['description'] = repo.p.string.strip()
# if no description is found
else:
repository['description'] = 'No description available for this repository.'
# add the programming language of the repository
programming_language = soup.find(attrs={'itemprop':'programmingLanguage'}).string.strip()
repository['programming_language'] = programming_language
# add our repo to our results
results.append(repository)
# return our list of repositories as the output of our function
return results
# Try it out
print(json.dumps(scrape_website('https://github.com/gvanrossum?tab=repositories'), indent=4))You may have noticed how we extracted the programming language. BeautifulSoup does not only allow us to search for information using HTML elements but also using attributes of the HTML elements. This is a simple trick to enhance accuracy when working with programming-related data sets.
Result
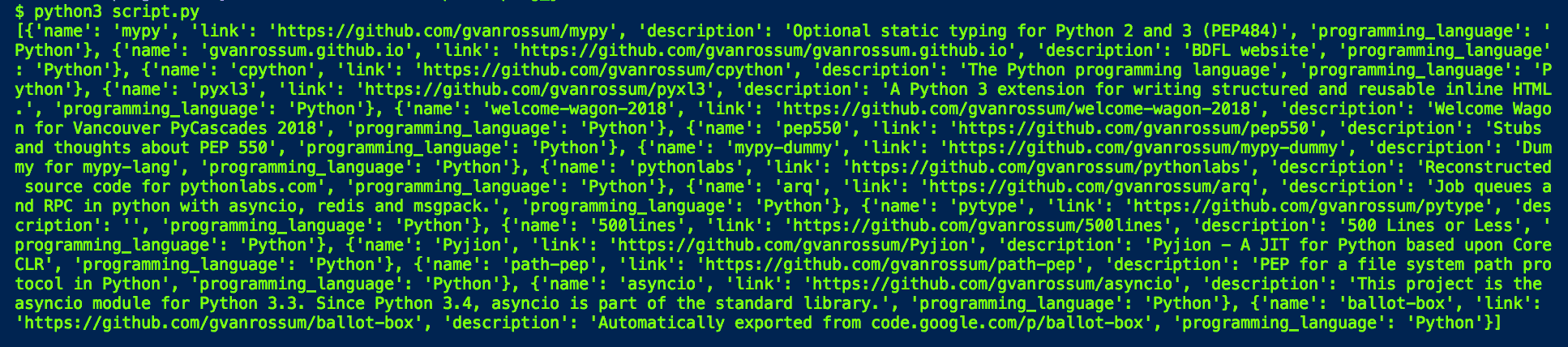
That’s it! You have successfully built your Github Repository Scraper and can test it on a bunch of other users’ repositories. You can check out Kite’s Github repository to easily access the code from this post and others from their Python series.
Now that you’ve built this scraper, there are myriad possibilities to enhance and utilize it. For example, this scraper can be modified to send a notification when a user adds a new repository. This would enable you to be aware of a developer’s latest work. (Remember when I mentioned that scraping tools are useful in finance? Maintaining your own scraper and setting up notifications for new data would be very useful in that setting).
Another idea would be to build a browser extension that displays a user’s repositories on hover at any page on Github. The scraper would feed data into an API that serves the extension. This data will be then served and displayed on the extension. You can also build a comparison tool for Github users based on the data you scrape, creating a ranking based on how actively users update their repositories or using keyword detection to find repositories that are relevant to you.
What’s Next?
We covered the basics of web scraping in this post and only touched a few of the many use cases for it. requests and beautifulsoup are powerful and relatively simple tools for web scraping, but you can also check out some of the more advanced libraries I highlighted at the beginning of the post for even more functionality. The next steps would be to build more complex scrapers that could be made of multiple scraping functions from many different sources. There are endless ways these scrapers can be integrated into any project that would benefit from data that’s publicly available on the web. Eventually, you’ll have so many web scraping functions running that you’ll have to start thinking about moving your computation to a home server or the cloud!
This post is a part of Kite’s new series on Python. You can check out the code from this and other posts on our GitHub repository.
Resources
 in San Francisco
in San Francisco