


Modeling Trees with SQLAlchemy ORM and Postgres Ltree
Table of Contents
- Background
- Setup
- Defining our model
- Usage
- Indexing
- Add a relationship
- Generating IDs
- Further usage examples
- Conclusion
- More resources
If you just want the recipe, skip here.
Background
When writing software, you’ll often encounter situations where a tree is the most appropriate data structure for working with hierarchical data. Although Python lacks a built-in native implementation of trees, it’s relatively straightforward to implement one yourself, especially with help from third-party libraries. In this post, I’ll walk through one approach to representing trees in Python using SQLAlchemy and the PostgreSQL Ltree data type.
Recall that a tree is made up of nodes that are connected by edges, with each node having one or zero (the root nodes) parent nodes, and zero (the leaf nodes) or more child nodes. As an example, here’s a tree showing the relationships between different categories of cats:
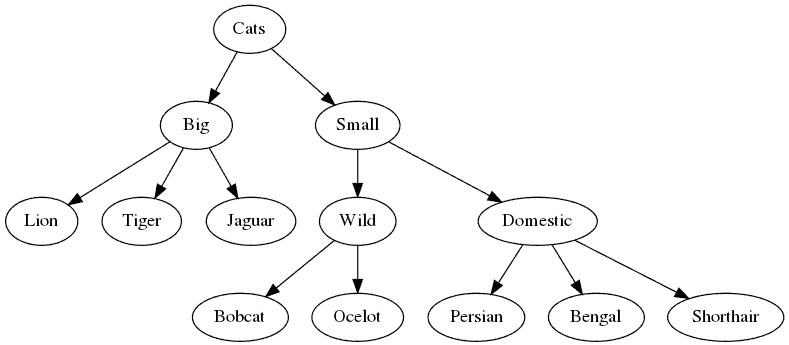
Unfortunately, trees can be an awkward fit for most traditional SQL databases. While relational databases are good at expressing the connections between different types of objects through foreign keys onto other tables, representing nested hierarchies of similar entities usually requires doing extra work and accepting some tradeoffs.
There are a variety of well-known approaches for storing trees in a relational database. Perhaps the most straightforward is the adjacency listpattern, where each row records one edge, represented by references to the parent and child nodes.The SQLAlchemy documentation contains an example of how to implement this pattern using its object-relational model (ORM). This method is simple and accommodates both inserting new nodes and updates that rearrange nodes and their subtrees. The tradeoff is that retrieving an entire subtree can be inefficient, involving expensive recursive queries.
Another common technique is using the materialized path pattern, in which each node keeps a record of the path to reach it from the root of the tree. This approach allows for fast inserts and fast queries, but moving an existing node to a different tree can be slow and expensive, as you have to rewrite the paths on any descendants of that node. Fortunately, there are many application workflows where moving nodes is rare or impossible, while adding new nodes and fetching entire subtrees are common operations. Imagine forum software that keeps track of nested trees of comments. Users can add new comments and delete old ones, but the application would never need to move or rearrange comments.
If you happen to be using Postgres as your database – you’re in luck! Postgres actually offers a custom data type called LTree specifically designed to record materialized paths for representing trees. Ltree is a powerful, flexible utility that allows your database to efficiently answer questions like, “What are all the descendants of this node?”, “What are all the siblings?”, “What’s the root of the tree containing this node?” and many more.
Setup
For this tutorial, you’ll need to install the following Python libraries: SQLAlchemy, SQLAlchemy-Utils, and the psycopg2 Postgres bindings. Your individual Python situation will vary, but I would suggest creating a virtualenv and installing the libraries there.
virtualenv .env --python=python3
source .env/bin/activate
pip install sqlalchemy sqlalchemy-utils psycopg2You’ll also need a running PostgreSQL instance. This tutorial was written using Postgres 10, but it should also work on Postgres 9. If you don’t have Postgres, you can consult their documentation for installation instructions specific to your operating system. Or, if you prefer, you can also grab a docker image, a Vagrant box, or just connect to a remote installation running on a server. Kite has also added the code from this post, including a Docker setup, in their github repository.
In any case, once you have Postgres up and running, you can create a database and a superuser role, connect to it and run CREATE EXTENSIONto make sure the Ltree extension is enabled:
CREATE EXTENSION IF NOT EXISTS ltree;If you get a permission denied error, your database user needs to be granted the superuser permission.
Defining our model
With those preliminaries out of the way, let’s move on to a basic model definition. This should look pretty familiar if you’ve used the SQLAlchemy ORM before:
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Node(Base):
__tablename__ = 'nodes'
id = Column(Integer, primary_key=True)
name = Column(String, nullable=False)
def __str__(self):
return self.name
def __repr__(self):
return 'Node({})'.format(self.name)In the above snippet, we’ve declared that we have an entity – Node – that has a primary key id, and a required name field. In real life, you might have any number of other interesting attributes on your models.
Next, we need to add a way of keeping track of the path between nodes. For this, we’re going to use the Ltree column type, which is available as part of the SQLAlchemy-Utils library:
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy_utils import LtreeType
Base = declarative_base()
class Node(Base):
__tablename__ = 'nodes'
id = Column(Integer, primary_key=True)
name = Column(String, nullable=False)
path = Column(LtreeType, nullable=False)
def __str__(self):
return self.name
def __repr__(self):
return 'Node({})'.format(self.name)Usage
Technically, this is all you need to get yourself up and running. We can now create nodes, store them in the database, and query for them in relation to one another. For example:
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy_utils import Ltree
engine = create_engine('postgresql://USERNAME:PASSWORD@localhost/MYDATABASE')
# https://docs.sqlalchemy.org/en/latest/core/metadata.html#creating-and-dropping-database-tables
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
session = Session()
cats = Node(name='cats', id=1, path=Ltree('1'))
lions = Node(name='lions', id=2, path=Ltree('1.2'))
tigers = Node(name='tigers', id=3, path=Ltree('1.3'))
bengal_tigers = Node(name='bengal_tigers', id=4, path=Ltree('1.3.4'))
session.add_all([cats, lions, tigers, bengal_tigers])
session.flush()
entire_tree = session.query(Node).filter(Node.path.descendant_of(cats.path)).all()
# [cats, tigers, lions, bengal_tigers]
ancestors = session.query(Node).filter(Node.path.ancestor_of(bengal_tigers.path)).all()
# [cats, tigers, bengal_tigers]
# Let's not persist this yet:
session.rollback()While this is a good start, it can be a bit of a pain to work with. We have to manually keep track of all the IDs and paths, there’s no obvious way of navigating from one node to another without going back to the SQLAlchemy session and running another query, and, in practice, those queries operate slowly on a large table because we haven’t set up an index on our path Ltree column.
Indexing
The missing index is easy to fix. Postgres supports several types of index on ltree columns. If you just pass index=True when defining your SQLAlchemy Column() , you’ll get a B-tree index, which can speed up simple comparison operations.
However, in order to take full advantage of Ltree capabilities, it’s better to create a GiST index. This can improve performance on a wider variety of query operations based on the hierarchical relationships between nodes. To add a GiST index in SQLAlchemy, we can pass a custom Index() in the __table_args__ attribute on our model. We add the postgres_using='gist' parameter in order to indicate the index type
from sqlalchemy import Column, Integer, String
from sqlalchemy import Index
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy_utils import LtreeType
Base = declarative_base()
class Node(Base):
__tablename__ = 'nodes'
id = Column(Integer, primary_key=True)
name = Column(String, nullable=False)
path = Column(LtreeType, nullable=False)
__table_args__ = (
Index('ix_nodes_path', path, postgresql_using="gist"),
)
def __str__(self):
return self.name
def __repr__(self):
return 'Node({})'.format(self.name)Add a relationship
In many cases, it’s convenient to be able to easily get the parent or child nodes from a node you’re working with. SQLAlchemy’s ORM offers a flexible relationship() construct that can be combined with the Ltree function subpath() to provide the desired interface.
from sqlalchemy.orm import relationship, remote, foreign
from sqlalchemy import func
from sqlalchemy import Column, Integer, String
from sqlalchemy import Index
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy_utils import LtreeType
Base = declarative_base()
class Node(Base):
__tablename__ = 'nodes'
id = Column(Integer, primary_key=True)
name = Column(String, nullable=False)
path = Column(LtreeType, nullable=False)
parent = relationship(
'Node',
primaryjoin=remote(path) == foreign(func.subpath(path, 0, -1)),
backref='children',
viewonly=True,
)
__table_args__ = (
Index('ix_nodes_path', path, postgresql_using="gist"),
)
def __str__(self):
return self.name
def __repr__(self):
return 'Node({})'.format(self.name)The bulk of this relationship is in the line:
primaryjoin=remote(path) == foreign(func.subpath(path, 0, -1)),Here, we’re telling SQLAlchemy to issue a JOIN looking for a row where the path column matches the output of the Postgres subpath() function on this node’s path column, which we’re treating as though it were a foreign key. The call subpath(path, 0, -1) is asking for all labels in the path except the last one. If you imagine path = Ltree('grandparent.parent.child'), then subpath(path, 0, -1) gives us Ltree('grandparent.parent') which is exactly what we want if we’re looking for the path of the parent node.
The backref helpfully gives us Node.children to go along with the Node.parent, and the viewonly parameter is just to be on the safe side. As mentioned above, manipulating hierarchies expressed as materialized paths requires rebuilding the whole tree, so you wouldn’t want to accidentally modify a single node’s path using this relationship.
Generating IDs
Rather than having to assign IDs to nodes ourselves, it’s much more convenient to generate IDs automatically from an auto-incrementing sequence. When you define an integer primary ID column in SQLAlchemy, this is the default behavior. Unfortunately, that ID isn’t available until you’ve flushed your ‘pending’ object to the database. This causes a problem for us, since we’d also like to incorporate that ID in the ltree path column.
One way around this issue is by creating an __init__() method for our Node that will pre-fetch the next ID value from the sequence, so it can be used in both the id and path columns. To do this, we’ll explicitly define a Sequence() to be associated with the id. In SQLAlchemy, calling execute() on a sequence object will fetch the next value for the sequence.
from sqlalchemy.orm import relationship, remote, foreign
from sqlalchemy import func
from sqlalchemy import Sequence, create_engine
from sqlalchemy import Column, Integer, String
from sqlalchemy import Index
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy_utils import LtreeType
engine = create_engine('postgresql://USER:PASSWORD@localhost/MYDATABASE')
Base = declarative_base()
id_seq = Sequence('nodes_id_seq')
class Node(Base):
__tablename__ = 'nodes'
id = Column(Integer, primary_key=True)
id = Column(Integer, id_seq, primary_key=True)
name = Column(String, nullable=False)
path = Column(LtreeType, nullable=False)
parent = relationship(
'Node',
primaryjoin=remote(path) == foreign(func.subpath(path, 0, -1)),
backref='children',
viewonly=True,
)
def __init__(self, name, parent=None):
_id = engine.execute(id_seq)
self.id = _id
self.name = name
ltree_id = Ltree(str(_id))
self.path = ltree_id if parent is None else parent.path + ltree_id
__table_args__ = (
Index('ix_nodes_path', path, postgresql_using="gist"),
)
def __str__(self):
return self.name
def __repr__(self):
return 'Node({})'.format(self.name)Note that in order for this to work, you need to have an engine instance connected to your database. Luckily, the call to get the next ID doesn’t have to happen in the context of a SQLAlchemy session.
As an option, another approach to avoid this preemptive fetching is to use a different type of ID. For example, UUID keys can be generated by your application – independently of a database sequence. Alternatively, if your data features good natural keys, you could use those as primary keys and in the Ltree path.
Recipe
Combining everything we’ve discussed and consolidating some imports, the full recipe ends up looking something like the code below. You can also find the full code associated with this post (including instructions for running this code in a Docker image!) in Kite’s github repository.
from sqlalchemy import Column, Integer, String, Sequence, Index
from sqlalchemy import func, create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship, remote, foreign
from sqlalchemy_utils import LtreeType, Ltree
Base = declarative_base()
engine = create_engine('postgresql://USER:PASSWORD@localhost/MYDATABASE')
id_seq = Sequence('nodes_id_seq')
class Node(Base):
__tablename__ = 'nodes'
id = Column(Integer, id_seq, primary_key=True)
name = Column(String, nullable=False)
path = Column(LtreeType, nullable=False)
parent = relationship(
'Node',
primaryjoin=(remote(path) == foreign(func.subpath(path, 0, -1))),
backref='children',
viewonly=True
)
def __init__(self, name, parent=None):
_id = engine.execute(id_seq)
self.id = _id
self.name = name
ltree_id = Ltree(str(_id))
self.path = ltree_id if parent is None else parent.path + ltree_id
__table_args__ = (
Index('ix_nodes_path', path, postgresql_using='gist'),
)
def __str__(self):
return self.name
def __repr__(self):
return 'Node({})'.format(self.name)
Base.metadata.create_all(engine)Further usage examples
from sqlalchemy import func
from sqlalchemy.orm import sessionmaker
from sqlalchemy.sql import expression
from sqlalchemy_utils.types.ltree import LQUERY
Session = sessionmaker(bind=engine)
session = Session()
# To create a tree like the example shown
# at the top of this post:
cats = Node('cats')
big = Node('big', parent=cats)
small = Node('small', parent=cats)
wild = Node('wild', parent=small)
domestic = Node('domestic', parent=small)
session.add_all((cats, big, small, wild, domestic))
for big_cat in ('lion', 'tiger', 'jaguar'):
session.add(Node(big_cat, parent=big))
for small_wildcat in ('ocelot', 'bobcat'):
session.add(Node(small_wildcat, parent=wild))
for domestic_cat in ('persian', 'bengal', 'shorthair'):
session.add(Node(domestic_cat, parent=domestic))
session.flush()
# To retrieve a whole subtree:
whole_subtree = session.query(Node).filter(Node.path.descendant_of(domestic.path)).all()
print('Whole subtree:', whole_subtree)
# [domestic, persian, bengal, shorthair]
# Get only the third layer of nodes:
third_layer = session.query(Node).filter(func.nlevel(Node.path) == 3).all()
print('Third layer:', third_layer)
# [wild, domestic, lion, tiger, jaguar]
# Get all the siblings of a node:
shorthair = session.query(Node).filter_by(name="shorthair").one()
siblings = session.query(Node).filter(
# We can use Python's slice notation on ltree paths:
Node.path.descendant_of(shorthair.path[:-1]),
func.nlevel(Node.path) == len(shorthair.path),
Node.id != shorthair.id,
).all()
print('Siblings of shorthair:', siblings)
# [persian, bengal]
# Using an LQuery to get immediate children of two parent nodes at different depths:
query = "*.%s|%s.*{1}" % (big.id, wild.id)
lquery = expression.cast(query, LQUERY)
immediate_children = session.query(Node).filter(Node.path.lquery(lquery)).all()
print('Immediate children of big and wild:', immediate_children)
# [lion, tiger, ocelot, jaguar, bobcat]The output:
Whole subtree: [Node(domestic), Node(persian), Node(bengal), Node(shorthair)]
Third layer: [Node(wild), Node(domestic), Node(lion), Node(tiger), Node(jaguar)]
Siblings of shorthair: [Node(persian), Node(bengal)]
Immediate children of big and wild: [Node(lion), Node(tiger), Node(jaguar), Node(ocelot), Node(bobcat)]These are just a few examples. The LQuery syntax is flexible enough to enable a wide variety of queries.
Conclusion
Sometimes we want the reliability and maturity of a relational database solution like PostgreSQL, but it can be hard to see how our data maps to the database format. The techniques in this article can be used to represent tree data in PostgreSQL using the elegant and mature Ltree datatype, conveniently exposed via the SQLAlchemy ORM. So, feel free to get some practice by re-working the examples above, and also checking out some related resources!
More resources
In addition to the excellent documentation for PostgreSQL and SQLAlchemy, these are some other resources that I found helpful when writing this post:
Using ltree for hierarchical structures in PostgreSQL
Using the Ltree Datatype in Postgres
Everything you need to know about tree data structures
This post is a part of Kite’s new series on Python. You can check out the code from this and other posts on our GitHub repository.
Resources
 in San Francisco
in San Francisco